



Machine Learning is like a magic word now - for sure you have heard something cool about it, a lot of developers tried to build some models using ready to use libraries like scikit-learn, but still some of us are affraid of it. But do you know that you can implement your first ML algorithm for your own. I read some time ago, not sure where, that k-Nearest neighbours is the first what you should try if you are interesting in ML.
Let's try to do it!
You may think that the best option for this task will be Python (because most of popular ML tools are written in it). I've implemented kNN in Ruby because of a few reasons:
- I know Ruby pretty well
- Code and syntax are easy to understand for people who don't know Ruby
- Because why not? :)
Before we will start, let's try with simple example.
Let's say that we have recorded some unknown for us animal with sound frequency 20.9 Hz and duration 2400 ms. We know that it's a cat, but we don't know for sure if is it a domestic cat or cheetah.
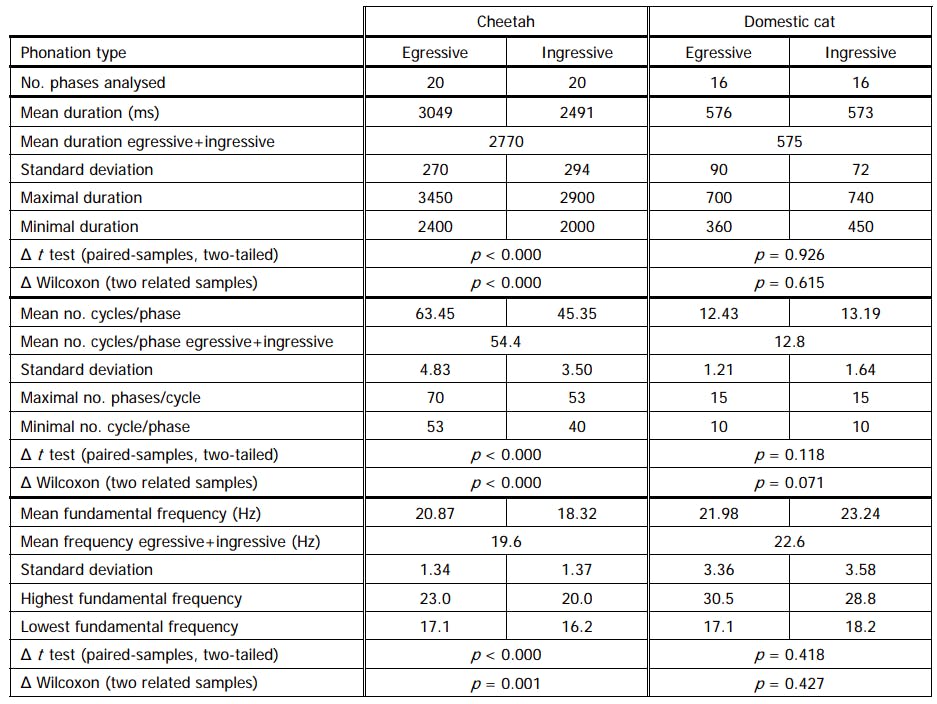
According to these data, we can see that the purring of these cats is slightly different (different duration, cycles/phase, frequency). Let's try to use this data to create simple, test dataset:
unknown_cat = { label: "unknown cat", frequency: 20.9, duration: 2400 }
dataset = [
{ label: "domestic_cat", frequency: 22.6, duration: 575 },
{ label: "cheetah", frequency: 19.6, duration: 2770 },
{ label: "domestic_cat", frequency: 21.98, duration: 576 },
{ label: "cheetah", frequency: 20.87, duration: 3049 },
{ label: "domestic_cat", frequency: 23.24, duration: 573 },
{ label: "cheetah", frequency: 18.32, duration: 2491 }
]
So, we have 6 examples in our dataset - 3 for domestic cats and 3 for cheetahs. We have also some unknown cat. Using these data, let's try to find out more about the unknown cat.
def cat_predictor(dataset, unknown_item)
max_similar_items = Math.sqrt(dataset.size).to_i
similar_items = {}
dataset.each do |dataset_el|
path = Math.sqrt(
(dataset_el[:frequency] - unknown_item[:frequency])**2 + (dataset_el[:duration] - unknown_item[:duration])**2
)
if similar_items.keys.size < max_similar_items || similar_items.keys.max > path
similar_items.delete(similar_items.keys.max) if similar_items.keys.size == max_similar_items
similar_items[path] = dataset_el
end
end
similar_items.map { |_path, item| item[:label] }.group_by(&:itself).transform_values(&:count).max_by(&:last)[0]
end
cat_predictor(dataset, unknown_cat)
# => cheetah
Before I start with more complex examples, I will try to explain what happens there. First, look at the picture below:
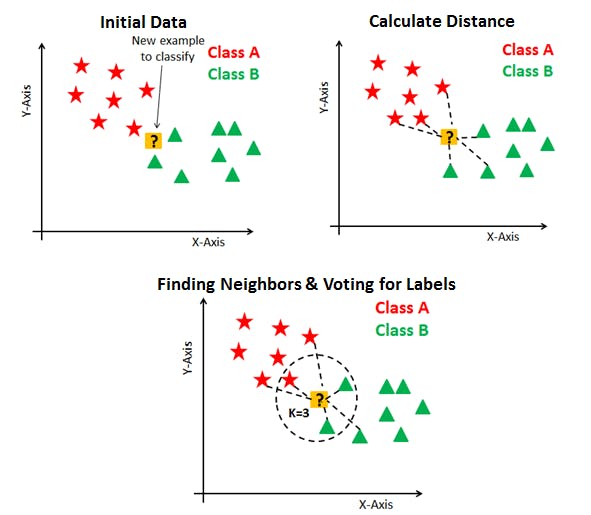 source: datacamp.com
source: datacamp.com
KNN is classification algorithm. Imagine that yellow point is our unknown cat, red points are domestic cat examples and green ones - cheetah examples. Like you can see we have to calculate "path" between each point from dataset and our unknown cat. To that we used a simple distance formula.
√(x1-x2)^2+(y1-y2)^2
The next important thing is the size of the set where we will be keeping the nearest examples (our "k") - I just calculated it by Math.sqrt(dataset.size).to_i, which means that "k" will have a square of dataset size.
After that starts the core of our algorithm. We count the length of the path for each element and add them to similar_items hash if:
- there is a "free space" for new item
- or the new value is lower than the current highest
After all we just group results and choose group which has more items. Quite easy, isn't it?

Movie rating prediction
The time has come for a more advanced example. I wanted to build model that can predict something, so I thought it would be cool if our example would be real-world example, so let's build a simple rating prediction system!
Let's say that we have some movie categories:
comedy_category = OpenStruct.new(id: 1, name: 'Comedy')
action_category = OpenStruct.new(id: 2, name: 'Action')
drama_category = OpenStruct.new(id: 3, name: 'Drama')
horror_category = OpenStruct.new(id: 4, name: 'Horror')
romance_category = OpenStruct.new(id: 5, name: 'Romance')
And of course users which objects contains some statistics:
patrycja = OpenStruct.new(id: 1, name: 'Patrycja', watched_movies: {
comedy_category.id => 3,
action_category.id => 4,
drama_category.id => 4,
horror_category.id => 1,
romance_category.id => 4
})
justyna = OpenStruct.new(id: 2, name: 'Justyna', watched_movies: {
comedy_category.id => 4,
action_category.id => 3,
drama_category.id => 5,
horror_category.id => 1,
romance_category.id => 5
})
morfeusz = OpenStruct.new(id: 3, name: 'Morfeusz', watched_movies: {
comedy_category.id => 2,
action_category.id => 5,
drama_category.id => 1,
horror_category.id => 3,
romance_category.id => 1
})
john = OpenStruct.new(id: 4, name: 'John', watched_movies: {
comedy_category.id => 5,
action_category.id => 1,
drama_category.id => 1,
horror_category.id => 5,
romance_category.id => 1
})
simon = OpenStruct.new(id: 5, name: 'Simon', watched_movies: {
comedy_category.id => 3,
action_category.id => 4,
drama_category.id => 3,
horror_category.id => 2,
romance_category.id => 4
})
angela = OpenStruct.new(id: 6, name: 'Angela', watched_movies: {
comedy_category.id => 2,
action_category.id => 3,
drama_category.id => 2,
horror_category.id => 1,
romance_category.id => 4
})
hans = OpenStruct.new(id: 7, name: 'Hans', watched_movies: {
comedy_category.id => 5,
action_category.id => 4,
drama_category.id => 4,
horror_category.id => 5,
romance_category.id => 5
})
users = [patrycja, justyna, morfeusz, john, simon, angela, hans]
Last but not least, we need our movie:
movie = OpenStruct.new(id: 1, name: 'Matrix', ratings: {
justyna.id => 5,
morfeusz.id => 4,
john.id => 2,
simon.id => 4,
angela.id => 2,
hans.id => 5
})
I've put them into OpenStruct objects, so we can treat them as for instance ActiveRecord objects.
Now we can start extend our previous algorithm to new requirements:
require 'ostruct'
class KnnModel
def initialize(dataset, new_item)
@dataset = dataset
@new_item = new_item
@neighbors_quantity = Math.sqrt(dataset.size).to_i
end
def build_model
shoritest_path = Float::INFINITY
nearest_neighbors = {}
(dataset - [new_item]).each do |dataset_el|
path = path_length(dataset_el)
if nearest_neighbors.keys.size < neighbors_quantity || nearest_neighbors.keys.max > path
nearest_neighbors.delete(nearest_neighbors.keys.max) if nearest_neighbors.keys.size == neighbors_quantity
nearest_neighbors[path] = dataset_el
end
end
Knn.new(nearest_neighbors)
end
private
attr_reader :dataset, :new_item, :neighbors_quantity, :neighbors
def path_length(dataset_el)
dimension_results = 0
new_item.watched_movies.keys.each do |id|
next if dataset_el.watched_movies[id].nil?
dimension_results += (dataset_el.watched_movies[id] - new_item.watched_movies[id])**2
end
Math.sqrt(dimension_results)
end
end
class Knn
attr_reader :neighbors
def initialize(nearest_neighbors)
@neighbors = nearest_neighbors
end
def predict_rating(movie)
neighbors_ratings = []
neighbors.values.each do |neighbor|
neighbors_ratings << movie.ratings[neighbor.id] if movie.ratings.keys.include?(neighbor.id)
end
return 'unpredictable average' if neighbors_ratings.empty?
count_avg_for_ratings(neighbors_ratings)
end
def find_user_who_like_similar_movies
neighbors[neighbors.keys.min].name
end
private
def count_avg_for_ratings(ratings)
ratings.instance_eval { reduce(:+) / size.to_f }
end
end
And the results are:
knn_model = KnnModel.new(users, patrycja).build_model
puts 'nearest neighbors: ' + knn_model.neighbors.map{|el| el.last.name}.join(', ')
puts 'user who like similar movies: ' + knn_model.find_user_who_like_similar_movies
puts 'predicted rating for movie: ' + knn_model.predict_rating(movie).to_s
# =>
# nearest neighbors: Justyna, Simon
# user who like similar movies: Simon
# predicted rating for movie: 4.5
As you can see, core of our code is similar to example with cats. First, we created kNN model in the same way as in previous example. Then we executed predict_rating method with movie as argument. This method is quite simple - it gets all ratings of nearest neighbors and counts their average.
Bonus
I wanted to implement more efficient kNN algorithm some time ago. I didn't focus on design at all, my goal was to calculate the model as soon as possible. I chose GOlang for this task, you can find repository on GitHub.
I added there some content generator, and package lib with config contant:
const (
MovieCategoriesNumber = 30
UsersNumber = 50000
MaxPredictCategories = 10
NearestNeighborsPart = 1000
)
I thought that it will be great if I can use multithreading (goroutines) for this task, so I added NearestNeighborsPart constant which determines the size of the batch. Before k-Nearest-Neighbors starts count the model - it splits whole model in a few batches and run them in separate threads. Then the results are joined into one model.
At the end I have some benchmarks:
- Benchmark with goroutines: 179.898931ms
- Benchmark without goroutines: 495.25129ms
- Benchmark with the same number of users and categories in Ruby: 1.586181sec
It's almost 10x faster than implementation in Ruby. Goroutines can give a kick for application performance, and at the same time are easy to implement, I recommend trying them out!